

一、前言
芯片采购网专注于整合国内外授权IC代理商现货资源,芯片库存实时查询,行业价格合理,采购方便IC芯片,国内专业芯片采购平台。
人工智能,人工智能(AI)广泛应用于各种应用。硬件、算法和数据是人工智能的三大支撑,其中硬件是指运行 AI 算法芯片及相应的计算平台。由于使用场景越来越多,需要处理的数据量越来越大,人们的需求也越来越高,这使得AI硬件平台上必须有效地运行算法。目前主要用于硬件。 GPU 神经网络并行计算,还有 FPGA 和 ASIC 也有未来异军突起的潜力。
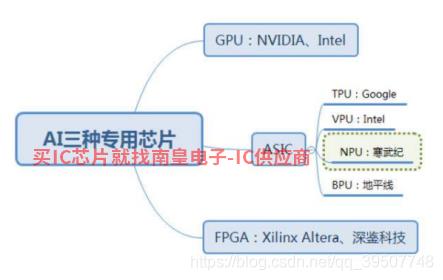
GPU它被称为图形处理器,是显卡的心脏 CPU 类似地,它只是一种专门从事图像操作的微处理器。GPU 在浮点计算和并行计算中,可以提供数十倍甚至数百倍 CPU 性能。但在应用于深度学习算法时,有三个局限性:
并行计算优势在应用过程中不能充分发挥
硬件结构固定不可编程
操作深度学习算法的效率远低于 ASIC 及 FPGA。
FPGA用户可以根据自己的需要重复编程,称为现场可编程门阵列。 GPU、CPU 相比之下,高、能耗低、可硬件编程等特点。FPGA 比GPU 功耗较低,比例较低 ASIC 开发时间短,成本低。FPGA也有三种限制:
基本单元的计算能力有限;
需要提高速度和功耗;
FPGA 比较贵。
ASIC(Application Specific Integrated Circuit)是为特殊目的设计的集成电路。不能重新编程,效率高,功耗低,但价格昂贵。近年来出现出现TPU、NPU、VPU、BPU各种令人眼花缭乱的芯片,本质上都属于ASIC。ASIC不同于 GPU 和 FPGA 定制的灵活性 ASIC 一旦制造完成,就不能改变,所以初始成本高,开发周期长,进入门槛高。目前大部分都是有的 AI 算法也擅长芯片研发的巨头,如 Google 的 TPU。与神经网络相关的算法完美适用,ASIC 优于性能和功耗 GPU 和 FPGA,TPU1 是传统 GPU 性能的 14-16 倍,NPU 是 GPU 的 118 倍。寒武纪已发布对外应用指令集,预计 ASIC 将是未来 AI 芯片的核心。
综上所述,在性能方面,ASIC优于其他几种计算方案。ASIC在众多芯片中,NPU性能非常突出,下面介绍一下NPU。
二、NPU介绍
所谓NPU(Neural network Processing Unit), 即神经网络处理器。顾名思义,它用电路模拟人类的神经元和突触结构!如果你想用电路模仿人类的神经元,你必须把每个神经元抽象成一个激励函数,它的输入是由连接神经元的输出和连接神经元的突触决定的。为了表达特定的知识,用户通常需要调整人工神经网络中的突触值、网络的拓扑结构等。这一过程称为学习。学习后,人工神经网络可以通过学习的知识来解决特定的问题。
由于深度学习的基本操作是处理神经元和突触,而传统的处理器指令集(包括x86和ARM等)是为了开发一般计算,其基本操作是算术操作(加减乘除)和逻辑操作(和或非),通常需要数百甚至数千个指令来完成神经元的处理,深度学习的处理效率不高。此时,我们必须找到一种新的方法来突破经典的冯・诺伊曼结构!
存储和处理在神经网络中是一体的,都体现在突触权重上。 而冯・在诺伊曼结构中,存储和处理是分开的,分别由存储器和计算器实现,两者之间存在巨大的差异。用现有的基于冯・经典的诺伊曼结构计算机(如X英伟达86处理器GPU)运行神经网络时,不可避免地会受到存储和处理分离结构的限制,从而影响效率。这也是专门针对人工智能的专业芯片对传统芯片具有一定先天优势的原因之一。
NPU典型代表国内寒武纪(Cambricon)芯片和IBM的TrueNorth。以中国寒武纪为例,2016年3月,中国科学院计算技术研究所陈云姬和陈天石研究小组提出了世界上第一个深度学习处理器指令集DianNaoYu。DianNaoYu指令可以直接处理大规模神经元和突触,一组神经元可以通过一个指令处理,并为芯片上神经元和突触数据的传输提供一系列特殊支持。
三、寒武纪NPU介绍
寒武纪科技于2016年发布了世界上第一个终端AI首款商用神经网络处理器(NPU)“寒武纪1A”(Cambricon-1A),智能手机、安全监控、可穿戴设备、无人机、智能驾驶等终端设备的主流智能算法能耗比完全超过传统CPU、GPU。其高性能硬件架构和软件支持Caffe、Tensorflow、MXnet等主流AI开发平台。可广泛应用于计算机视觉、语音识别、自然语言处理等智能处理的关键领域。
2017年,寒武纪科技发布了第二代NPU寒武纪1的架构H”(Cambricon-1H),该系列比第一代产品1A该系列的能效比提高了数倍,可广泛应用于计算机视觉、语言识别、自然语言处理等智能处理的关键领域。其中,Cambricon-1H16版本的IP作为1H2566系列高性能版MAC 5126位浮点运算器MAC 8位定点运算器。在1GHz在主频下,16位浮点神经网络的峰值速度为0.5Tops;8位定点神经网络运算的峰值速度为1Tops。Cambricon-1H8版本IP作为1H512MAC 8位定点运算器。在1GHz在主频下,8位定点神经网络运算的峰值速度为1Tops。Cambricon-1H8mini版本IP作为1H2566系列轻量级版MAC 8位定点运算器。在1GHz在主频下,8位定点神经网络的峰值速度为0.5Tops。
2018年,寒武纪科技发布了第三代IP寒武纪1产品M”(Cambricon-1M),世界上第一个台积电7nm工艺制造,能耗比5Tops/W,即每瓦特运算5万亿次,提供2Tops、4Tops、8Tops满足不同场景、不同量级的三种规模处理器核AI处理需求,支持多核互联。寒武纪1M前两代处理器延续IP产品寒武纪1H/1A卓越的TracoPower代理单个处理器核可以支持完整性CNN、RNN、SOM进一步支持多元化的深度学习模式SVM、k-NN、k-Means、决策树等经典机器学习算法支持本地培训,为视觉、语音、自然语言处理和各种经典机器学习任务提供灵活高效的计算平台,可广泛应用于智能手机、智能扬声器、智能摄像头、智能驾驶等领域。
四、Cambricon-1A NPU应用
这里首先介绍华为海思麒麟970手机处理器,因为它是世界上第一个人工智能移动计算平台,是业内第一个独立的NPU(Neural Network Processing Unit)手机芯片专用硬件处理单元。麒麟970创新集成NPU创新设计了专用硬件处理单元HiAI移动计算架构,它AI性能密度明显优于CPU和GPU。相较于四个Cortex-A73核心处理相同AI任务,新的异构计算架构有约 50 倍能效和 25 性能优势倍,图像识别速度可达2000张/分钟左右。如此强大NPU寒武纪使用的专用硬件处理单元Cambricon-1A系列的IP,即麒麟970芯片集成寒武纪1A处理器作为其核心人工智能处理单元(NPU)。
――――――――――――――――
版权声明:本文为CSDN博主「耐心的小黑」遵循原创文章CC 4.0 BY-SA版权协议,请附上原始来源链接和本声明。
原文链接:https://blog.csdn.net/qq_39507748/article/details/109402395




















- 苹果突然变脸
- 长电科技MEMS传感器包装技术
- 华为:预计到 2030 全球物联网年规模将达到100亿
- 用于Skywater Foundry 130 nm节点开源工艺设计套件
- Pixelworks逐点半导体助力vivo S15 Pro拉满手游的氛围
- ISELED联盟迎来了三名新成员
- 特斯拉Autopilot系统值得信赖吗?
- BOE(京东方)电子价签产品获得行业首份碳足迹评估报告
- 比亚迪刀片最强对手!宁德时代推出麒麟电池 能源水平行业最高
- 华为胡厚坤谈元宇宙:炒作期越热闹越冷静,谈整体策略还早
- 英飞凌批准了欧盟委员会第三条无线电设备指令.3 (d)、(e)、(f)欢迎条款授权条款
- 骁龙8 助力一加Ace Pro创造性能手机的新标杆
